
[회고] 채팅 애플리케이션 개발 회고 - RDBMS에서 NoSQL(DynamoDB)로 전환하며 배운 것들
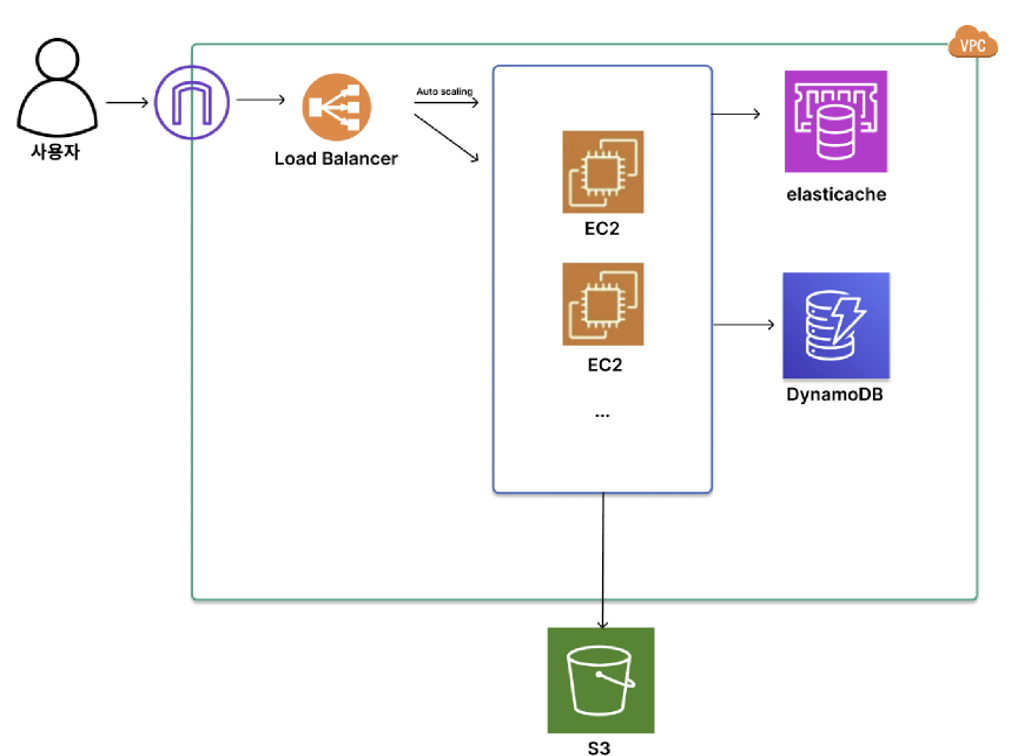
3-2학기를 마치면서 광운대학교 AWS Cloud Club 소모임 활동의 일환으로 진행한 채팅 애플리케이션 개발 프로젝트 에 대한 회고록을 작성하고자 한다.
Spring Boot 기반 백엔드와 AWS 인프라를 활용해, 실제 서비스에 가까운 채팅 시스템을 설계하고 구현하는 것을 목표로 했다.
프론트엔드는 소모임장님이 미리 만들어두셨다.
프로젝트를 진행하면서 단순히 기능을 구현한다를 넘어서, 도메인 특성에 맞는 데이터베이스 선택과 설계가 얼마나 중요한지를 깊이 고민하게 되었다.
프로젝트의 개발 흐름은 크게 세 가지로 나눌 수 있었는데, 인증과 사용자/채팅 데이터를 처리하는 백엔드 API 영역, 실시간 채팅을 담당하는 WebSocket 통신 영역, 그리고 AWS 인프라 및 배포 환경을 구성하는 아키텍처 영역이다.
이 중 나는 백엔드 API 영역을 담당하여, JWT 기반 인증/인가 로직과 DynamoDB 설계 및 연동을 포함한 auth, user, chat 도메인의 REST API를 구현했다.
처음의 설계: RDBMS 기반 ERD
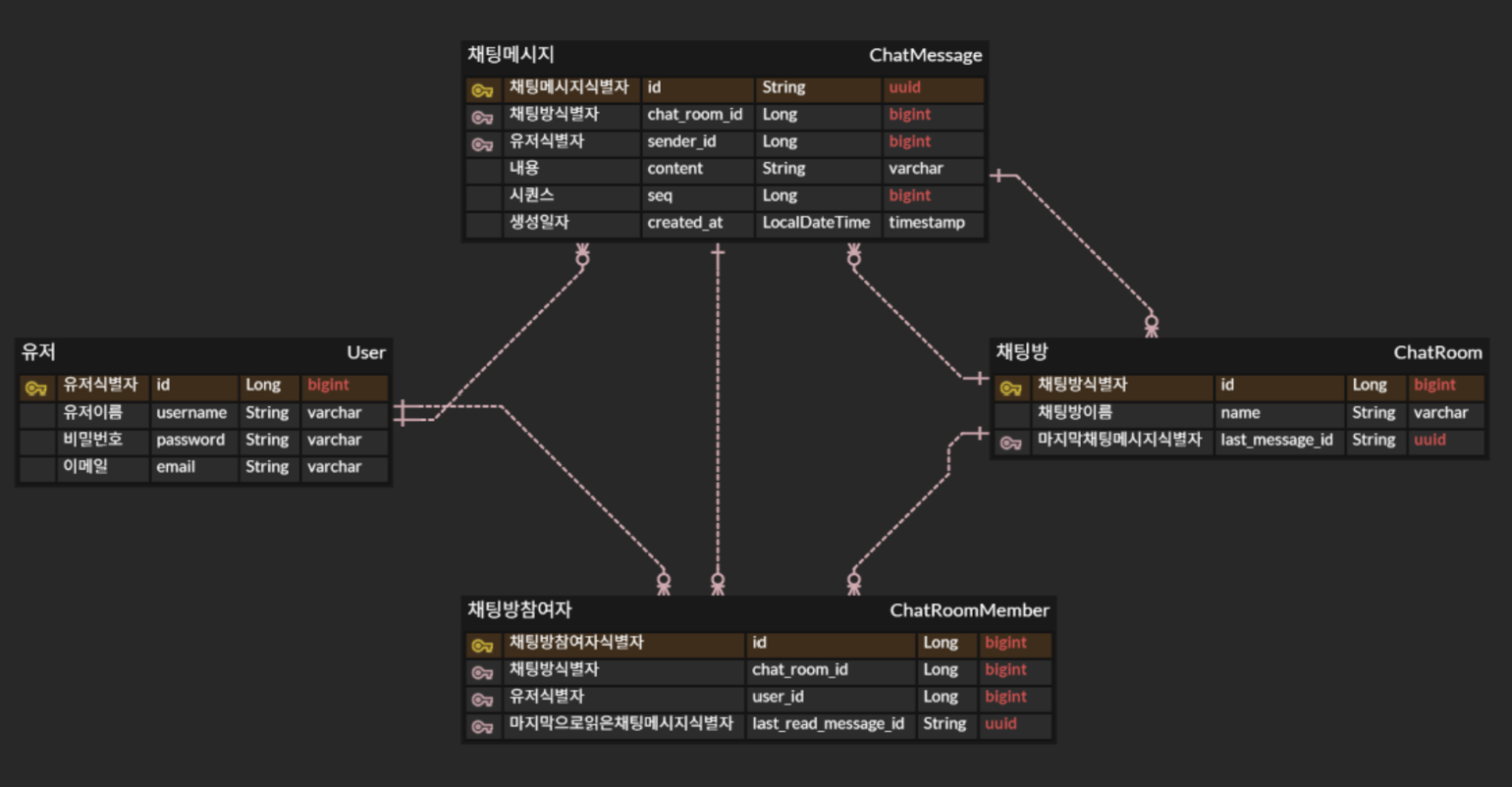
프로젝트 초반에는 자연스럽게 관계형 데이터베이스(RDBMS)를 기준으로 ERD를 설계했다.
- User
- ChatRoom
- ChatMessage
- ChatRoomMember
각 엔티티 간의 관계를 정규화하고, 외래 키와 JOIN을 통해 데이터를 조회하는 구조였다.
이 설계는 정합성과 구조적인 측면에서는 깔끔했지만, 채팅 도메인의 특성을 깊이 고려한 결과 몇 가지 의문이 생기기 시작했다.
채팅 도메인의 특성과 문제 인식
채팅 애플리케이션은 일반적인 CRUD 중심 서비스와 성격이 다르다.
- 유저가 어느 정도 있다는 가정 하에, 메시지는 초당 매우 많이 생성된다.
- 대부분의 메시지는 생성 이후 수정되지 않는 데이터이다.
- 메시지 간 관계(JOIN)보다 쓰기 성능이 훨씬 중요하다.
- 채팅방에는 매우 많은 사용자가 동시에 접속 가능하며, 접속하여 채팅할 수 있다.
이러한 특성은 정규화 + JOIN 기반의 RDBMS 설계와는 맞지 않는 부분이 많았다.
강한 트랜잭션 일관성보다는 지연되지 않는 것과 쓰기 성능이 중요했다.
RDBMS -> NoSQL 전환 결정
결국 우리는 데이터베이스 선택을 데이터의 형태 가 아니라 도메인의 접근 패턴과 데이터의 특성 을 기준으로 다시 판단했다.
그 결과, 채팅 애플리케이션의 핵심 특징 및 요구사항은 다음과 같았다.
- 쓰기 성능이 좋아야 한다.
- 수평으로 확장하기 좋아야 한다.
- 조회 패턴이 비교적 단순하다. (최신순 정렬 등)
- JOIN이 중요하지 않은 데이터 접근이 많다.
이는 분산 Key-Value 저장소가 잘하는 영역이었고, 이에 따라 NoSQL 기반 DynamoDB로의 전환을 결정하게 되었다.
DynamoDB 기반 데이터 모델링
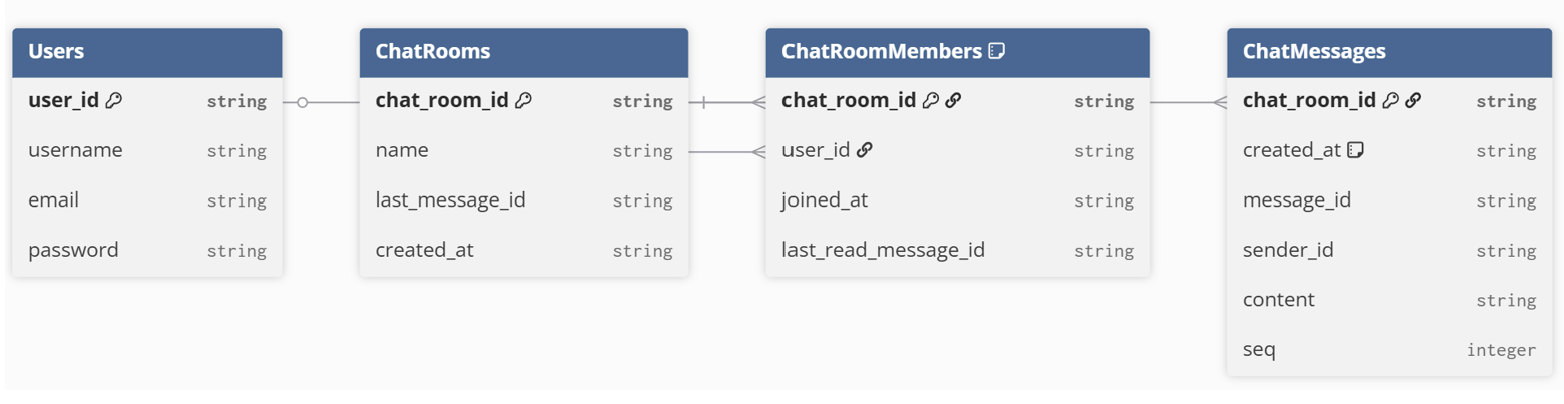
NoSQL로 전환하면서 가장 크게 달라진 점은 ERD를 관계 가 아닌 조회 패턴 중심으로 다시 설계했다는 것이다.
주요 설계 포인트
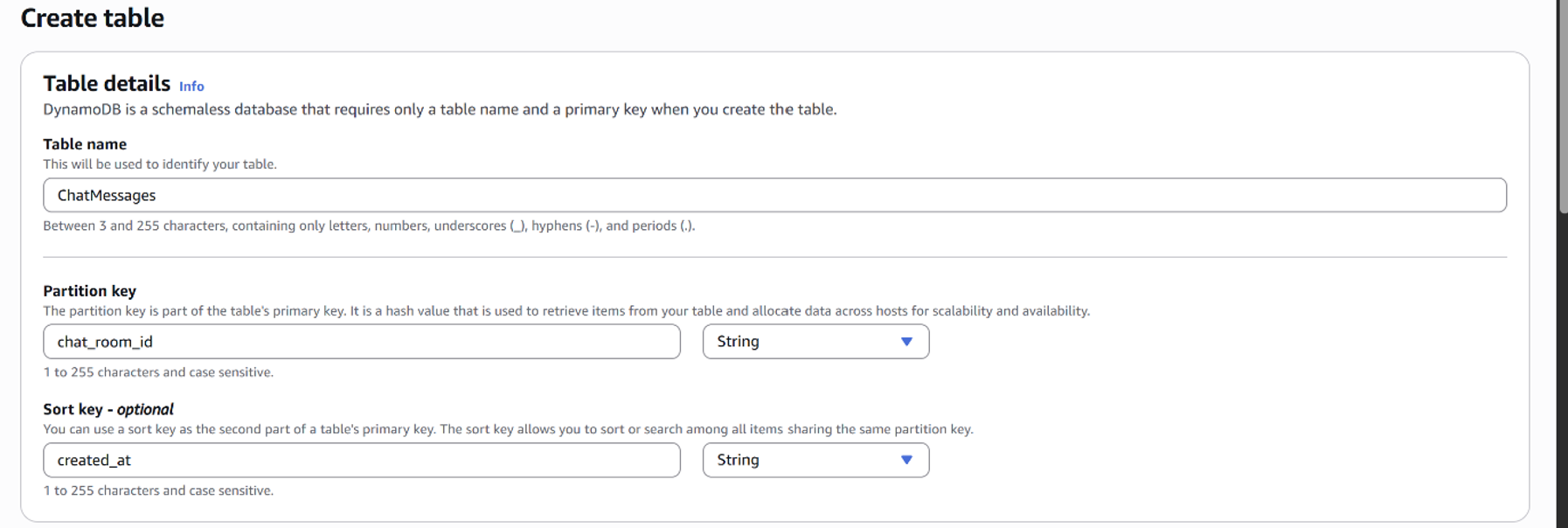
ChatMessages
Partition Key로 chat_room_id를, Sort Key로 created_at을 두어 채팅방별 시간순 메시지 조회에 최적화하였다.
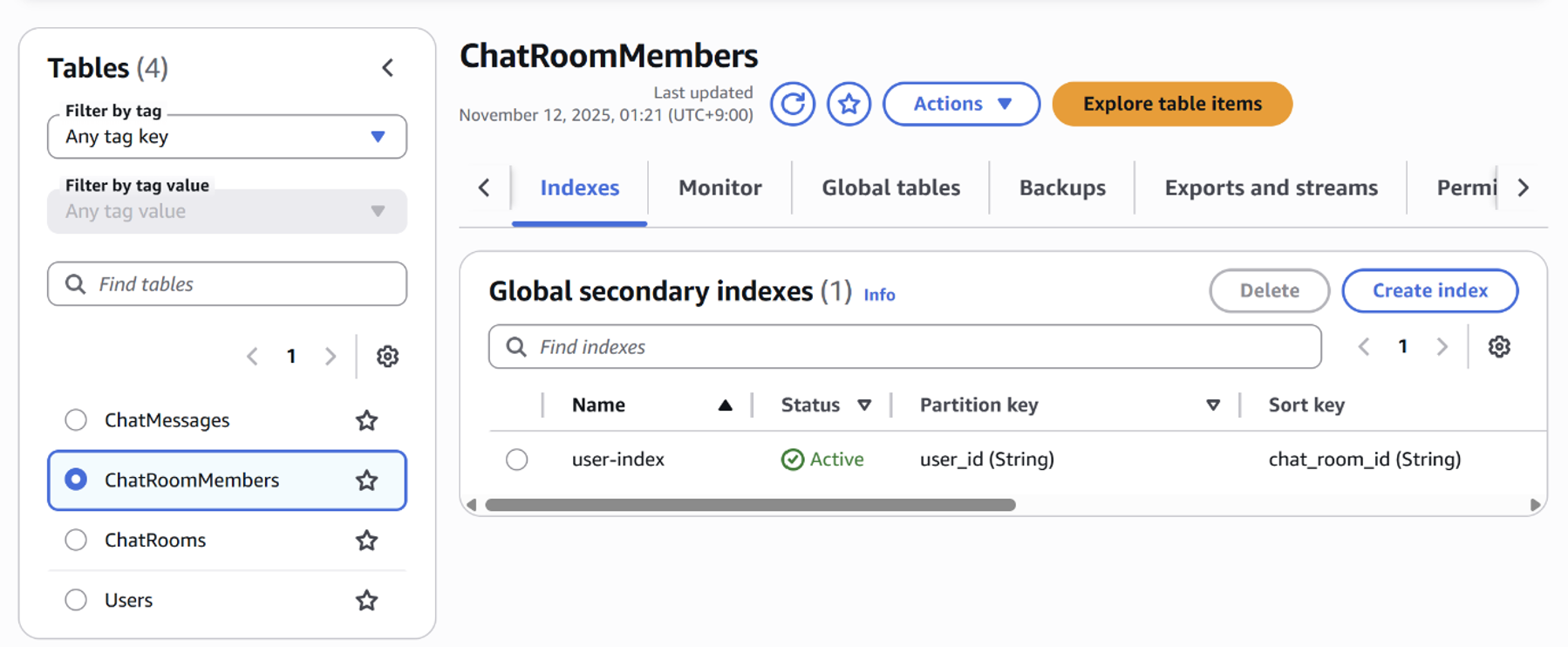
ChatRoomMembers
기본 Partition Key로 chat_room_id를, Sort Key로 user_id를 두었고, GSI(user-index)로 Partition Key: user_id, Sort Key: chat_room_id를 두어 사용자가 참여 중인 채팅방 목록 조회 를 지원하도록 한다.
여기서 GSI는 Global Secondary Index로, 테이블의 기본 키와는 다른 Partition Key/Sort Key 조합으로 데이터를 조회할 수 있도록 만든 보조 인덱스이다. 이를 통해 여러 조회 패턴을 하나의 테이블에서 지원할 수 있다. 내부적으로는 별도의 테이블처럼 데이터가 복제되어 저장되며, Global이라는 단어가 붙은 이유는 어떤 파티션에 있든 전역적으로 조회가 가능하기 때문이다.
또한 DynamoDB의 특성을 고려해 Partition Key/Sort Key를 string 타입으로 통일했다. 이는 AWS 공식 문서에서 권장하는 방식이며, 문자열 기반 정렬이 시간 순 조회와 해시 분산 측면에서 유리하기 때문이라고 한다.
JOIN이 없는 설계에 대한 이해
DynamoDB에서는 SQL처럼 JOIN 연산을 수행하지 않는다. 대신 조회 시점에 JOIN을 하는 것이 아니라, 설계 시점에 데이터를 비정규화하여 함께 조회되도록 저장한다.
즉, JOIN이 필요 없도록 저장한다.
이 관점의 전환은 NoSQL을 이해하는 데 있어 가장 중요한 학습 포인트였다.
최종 발표에서 받은 질문도 NoSQL의 JOIN과 관련된 질문이었는데, 잘 대답하지 못해서 아쉬웠다.
다시 정리하면
DynamoDB는 JOIN을 런타임에 수행하지 않기 때문에 JOIN이 필요한 데이터는 미리 하나의 item이나 동일한 Partition Key로 묶어서 저장하는 방식으로 설계한다. 즉, 미리 함께 조회될 형태에 맞게 데이터를 비정규화하여 저장한다.
구체적으로는 Single Table Design을 통해 관련 데이터를 같은 Partition Key로 저장하여 한 번의 쿼리로 함께 조회되도록 설계한다. 이를 통해 JOIN 없이도 유사한 효과를 낸다.
느낀 점
이번 프로젝트를 통해 얻은 가장 큰 교훈은 데이터베이스의 선택은 기술 스택의 문제가 아니라 도메인 이해의 문제라는 점 이다.
RDBMS와 NoSQL 중 무엇이 더 좋은가가 아니라, 우리 서비스의 접근 패턴과 데이터 특성에 무엇이 더 적합한가를 설명할 수 있어야 한다는 점을 배웠다.
단순히 DynamoDB를 써봤다에서 끝나는 것이 아니라, 왜 이 선택이 합리적인지 설명할 수 있게 되었다는 점에서 의미 있는 프로젝트였다고 생각한다.
공부를 하면 할수록 느끼는 거지만, 정말 배울 게 많다. 그리고 머리로 이해하고 있는 것과 말로 설명할 수 있는 것은 분명히 다르다…
Leave a comment