
[알고리즘] 최소 신장 트리(Minimum Spanning Tree)
이번 포스팅에서는 최소 신장 트리(Minimum Spanning Tree) 에 대해 다루려고 한다.
최소 신장 트리는 그리디 알고리즘(Greedy Algorithm) 을 기반으로 동작한다.
그리디 알고리즘이 생소하다면 지난 포스팅을 보고 오면 흐름을 더 잘 이해할 수 있다.
👉 [알고리즘] 그리디 알고리즘(Greedy Algorithm) - 거스름돈 문제로 이해하기
그리디 알고리즘과 최소 신장 트리
최소 신장 트리를 구할 때 각 단계에서 가장 이득이 되는 선택을 반복 한다는 점에서 그리디한 접근(Greedy Approach)을 따른다.
그리디 알고리즘은 일단 1번 선택하면 번복하지 않고, 계속 선택하고 끝이기 때문에 지역적으로 최적인 선택의 집합이 정말 전체적으로도 최적인지 는 문제에 따라 다르다.
따라서 항상 그 선택의 정당성 을 증명 해야 한다.
일반적인 그리디 알고리즘의 구조는 다음과 같다.
- Selection Procedure (최선의 선택)
- Feasibility Check (잘못된 선택인지 확인)
- Solution Check (해결이 되었는지 확인)
이를 의사코드(Pseudocode)로 표현해보면,
GreedyAlgorithm():
S = ∅
while (해가 완성되지 않았다면):
x = 선택 가능한 후보 중 최선의 선택 // Selection Procedure
if (x가 유효하지 않다면): // Feasibility Check
continue // 다음 후보 고려
S = S ∪ {x} // 현재 선택을 해에 포함시킴
if (S가 전체 해가 되었다면): // Solution Check
return S
return 미완성 또는 해가 없음
이러한 알고리즘의 프로세스대로 진행할 때 최적해를 구할 수 있는 문제 중 하나가 바로 최소 신장 트리(Minimum Spanning Tree)이다.
최소 신장 트리(Minimum Spanning Tree)란?
최소 신장 트리는 다음과 같은 그래프에서 정의된다.
- Undirected Graph (edge에 방향이 없는 그래프)
- Connected Graph (모든 vertex가 연결된 그래프, 즉 섬이 없는 그래프)
- Acyclic Graph (사이클이 없는 그래프, 즉 자기 자신으로 돌아오는 path가 없는 그래프)
이 세 그래프의 교집합이 바로 Tree 이다.
그럼, 이제 신장(Spanning) 이라는 단어의 뜻이 무엇인지 알아야 할텐데,
신장(Spanning)은 “생성”이라는 뜻을 가지고 있다.
뜻이 모호하다.
모 대학 알고리즘 강의에서 소개된 용어의 정의를 가져와봤다.
Spanning Tree for undirected graph
-> a connected subgraph that contains all the vertices in G and is a tree
Minimum Spanning Tree for undirected graph
-> a spanning tree of G with minimum weight
이를 토대로 정리해보면, 최소 신장 트리는 주어진 그래프의 모든 정점을 포함하며, 사이클이 없는 트리 형태의 부분 그래프 중 엣지 가중치의 합이 최소인 부분 그래프이다.
무슨 말인지 이해가 잘 안 될 것이다.
그림을 통해서 이해해보자.
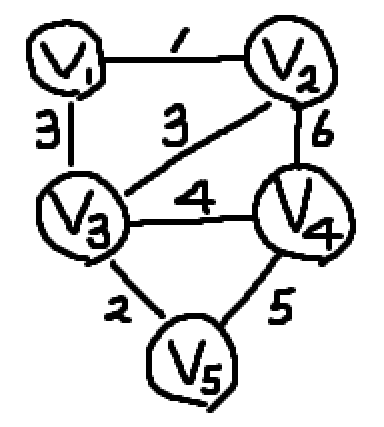
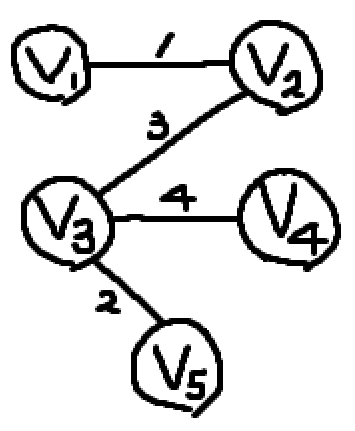
위와 같은 그래프가 있다.
이 그래프의 Spanning Tree를 구해보자.
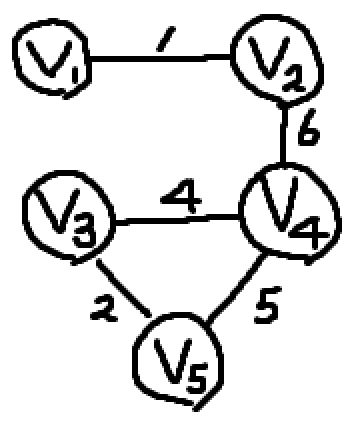
이 그래프는 위 그래프의 Spanning Tree일까?
안타깝게도, 그래프의 아래쪽을 보면 Cycle이 존재하기 때문에 이 그래프는 Spanning Tree가 될 수 없다.
정확하게는 Cycle이 존재하므로 Tree가 될 수 없다.
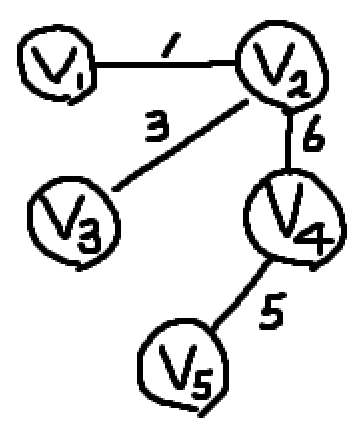
그렇다면 이 그래프는 Spanning Tree일까?
그렇다. 이 그래프는 주어진 그래프의 모든 정점을 포함하며, 사이클이 없는 트리 형태의 부분 그래프이기 때문에 Spanning Tree이다.
이제 어느 정도 감이 왔을 거라고 생각한다.
이러한 Spanning Tree는 그래프에서 여러 개가 존재할 수 있다. 모든 Spanning Tree 중 엣지 가중치의 합이 최소인 Spanning Tree가 바로 최소 신장 트리(Minimum Spanning Tree)이다.
그리고 이러한 최소 신장 트리는 바로 그리디 알고리즘으로 쉽게 구할 수 있다.
참고로, 그래프에서 최소 신장 트리는 여러 개가 나올 수 있다. 이 그래프에서 최소 신장 트리는 두 개가 있다.
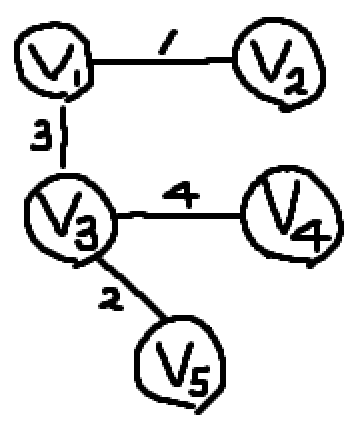
최소 신장 트리를 구하는 방법 - Prim’s Algorithm
최소 신장 트리를 구하는 방법으로 가장 널리 알려진 알고리즘은 두 개가 있다.
프림의 알고리즘과 크루스칼의 알고리즘이다. (여기서 프림과 크루스칼은 사람의 이름이다.)
먼저 프림의 알고리즘에 대해 소개하겠다.
프림의 알고리즘 아이디어 요약
트리 내 한 정점에서 시작해, 인접한 가장 짧은 edge를 가진 정점을 선택하며 정점을 확장해나간다. 이 과정에서 트리 구조는 유지된다.
프림 알고리즘의 Pseudocode
F = ∅ // F는 edge의 집합, vertex 개수 - 1 만큼의 edge가 필요
Y = {v₁} // Y는 vertex의 부분집합
while (문제가 해결되지 않은 경우):
V - Y에 있는 vertex 중 Y와 가장 가까운 vertex 선택 // V는 모든 vertex의 집합
해당 vertex를 Y에 추가
해당 vertex와 Y 사이의 edge를 F에 추가
if (Y == V): // 모든 정점이 포함되었으면
문제 해결 완료
프림의 알고리즘은 다음과 같은 절차로 구성된다.
Y: 현재 선택된 vertex들의 집합F: 최소 신장 트리를 구성할 edge들의 집합
반복적으로 Y에 가장 가까운 정점을 선택하며 트리를 확장해간다.
프림 알고리즘 구현
그렇다면 이 프림 알고리즘을 실제로 어떻게 구현할까?
더 좋은 자료구조가 있을 수 있지만, 이해를 쉽게 하기 위해 배열을 사용해보자.
[C++]
#include <iostream>
#include <climits>
using namespace std;
const int V = 5; // 정점 수
void prim(int W[V][V]) {
int nearest[V]; // nearest[i] = Y에 있는 V_i와 가장 가까운 정점의 번호
int distance[V]; // distance[i] = V_i와 nearest[i] 간의 거리(edge weight)
bool Y[V]; // Y[i] = true이면 트리에 포함된 정점(즉, Y 집합)
// 1. 초기화
for (int i = 0; i < V; i++) {
nearest[i] = 0; // V_1밖에 없는 상태
distance[i] = W[0][i]; // W[V_1][i]로 초기화
Y[i] = false; // 아직 트리에 포함되지 않음
}
Y[0] = true; // V_1을 시작점으로 선택
int totalWeight = 0;
cout << "선택된 간선들(u - v : weight):\n";
// 5. 모든 정점이 포함될 때까지 반복
for (int step = 0; step < V - 1; step++) {
int min = INT_MAX;
int vnear = -1;
// 2. distance 배열에서 최솟값을 갖는 정점 선택
for (int i = 1; i < V; i++) {
if (!Y[i] && distance[i] < min) {
min = distance[i];
vnear = i;
}
}
if (vnear == -1)
break;
// 3. 그 정점을 트리에 추가, 간선 출력
Y[vnear] = true;
totalWeight += W[vnear][nearest[vnear]];
cout << "V" << nearest[vnear] + 1 << " - V" << vnear + 1 << " : " << W[vnear][nearest[vnear]] << "\n";
// 4. 연결되지 않은 정점들에 대해 nearest, distance 갱신
for (int i = 1; i < V; i++) {
if (!Y[i] && W[i][vnear] < distance[i]) {
distance[i] = W[i][vnear];
nearest[i] = vnear;
}
}
}
cout << "총 가중치 : " << totalWeight << "\n";
}
int main() {
int W[V][V] = {
{0, 1, 3, INT_MAX, INT_MAX},
{1, 0, INT_MAX, 6, INT_MAX},
{3, INT_MAX, 0, 4, 2},
{INT_MAX, 6, 4, 0, 5},
{INT_MAX, INT_MAX, 2, 5, 0}
};
prim(W);
return 0;
}
🔽 출력 :
선택된 간선들(u - v : weight):
V1 - V2 : 1
V1 - V3 : 3
V3 - V5 : 2
V3 - V4 : 4
총 가중치 : 10
Y(vertex subset)와 가장 가까운 vertex 찾기를 반복한다.
입력으로
W[i][j] (가중치 테이블 - symmetric, W[j][i]와 같다)
nearest[i] (V_i와 가장 가까운 Y에 있는 vertex 번호)
distance[i] (V_i와 nearest[i] 사이의 edge weight, 즉 V_i와 가장 가까운 Y에 있는 vertex 간 거리)
을 입력받는다.
distance가 가장 작을 때의 nearest 값을 Y에 반복적으로 넣어야 한다.
가장 작은 edge weight을 가진 vertex를 고르기 위해 distance가 필요하며, 고르면 연결된 vertex가 무엇인지 알아야 하므로 nearest가 필요하다.
nearest[i]는 V_1밖에 없는 상태에서 출발하므로 0으로 초기화하고, distance[i]는 W[0][i]로 초기화한다.
요약
- 아무 정점을 시작점으로 선택 (여기서는 V_1 선택)
- distance 배열에서 최솟값을 갖는 정점 선택
- 그 정점을 트리에 추가
- 연결되지 않은 정점들에 대해 nearest, distance 갱신
- 모든 정점이 포함될 때까지 반복
시간 복잡도는 2중 for 문을 사용하므로 대충 Θ(n^2)이며, 알고리즘에 트리에 포함되지 않은 정점들 중에서 distance[i] 값이 가장 작은 정점을 반복적으로 선택하고 넣는 행위가 있으므로 heap(priority queue)을 쓰면 시간 복잡도를 logn만큼 더 줄일 수 있을 것이다.
보통, 좋은 자료구조 선택 시 알고리즘의 시간 복잡도를 logn만큼 더 줄일 수 있다.
프림 알고리즘의 궁극적인 버전은 피보나치 힙이라는 자료구조를 쓰는 것인데, 관심 있는 사람은 이에 대해 더 찾아보기 바란다.
최소 신장 트리를 구하는 방법 - Kruskal’s Algorithm
크루스칼의 알고리즘 아이디어 요약
가장 짧은 edge부터 선택하면서, Cycle이 생기지 않도록 두 정점을 잇고 정점들의 집합을 병합해나간다.
크루스칼 알고리즘의 Pseudocode
1. F = ∅ // F는 선택된 edge들의 집합
2. 정점마다 집합 생성 // 여기서 집합은 서로소 집합(Disjoint set)
3. edge를 가중치 기준으로 오름차순 정렬
4. 반복
다음 edge 선택
선택된 edge가 서로 다른 집합(Disjoint set)에 속한 두 정점을 연결한다면, 두 집합을 합침(Union)
이후 해당 edge를 F에 추가
5. 모든 정점이 하나의 집합으로 병합되면, 알고리즘 종료
즉, edge를 가중치 기준으로 정렬한 뒤, Cycle이 생기지 않도록 edge를 하나씩 선택, 정점을 연결해서 최소 신장 트리를 구성한다.
여기서 Disjoint set이 좀 생소할 것이다.
Disjoint set(서로소 집합)은 자료구조 중 하나로, 원소들이 서로 겹치지 않는 여러 개의 집합을 관리할 때 쓰는 자료구조이다.
주로 집합을 합치거나 어느 집합에 속해 있는지 확인할 때 사용한다.
Disjoint set은 C++ STL에 없기 때문에 직접 구현해서 사용해야 한다.
크루스칼 알고리즘 구현
다시, 크루스칼 알고리즘은 edge를 가중치 기준으로 정렬한 뒤 하나씩 선택하면서 Cycle이 생기는지 판단하고 생기지 않으면 선택한다. 즉, vertex 간 연결 정보를 인접 행렬(Adjacency matrix)로 다루는 것보다, edge list로 직접 다루는 것이 시간과 구현 면에서 효율적이다.
다만 일반적인 알고리즘 문제 풀이에서 인접 행렬로 주어진 그래프를 입력으로 받는 경우가 대부분이므로 그래프를 edge list로 바꾸어서 문제를 해결하는 알고리즘을 소개하고자 한다.
[C++]
#include <iostream>
#include <vector>
#include <algorithm>
#include <climits>
using namespace std;
const int V = 5;
// 간선 구조체
struct Edge {
int u, v; // u는 출발 정점, v는 도착 정점
int weight;
};
// 가중치 기준 정렬(sort) 시 오름차순으로 정렬하기 위한 비교 함수
bool compare(const Edge& a, const Edge& b) {
return a.weight < b.weight;
}
// Disjoint Set
class DisjointSet {
private:
vector<int> parent, rank; // parent는 각 원소의 부모, 루트면 자기 자신
// rank는 트리의 깊이 추적 용도(Union 시 작은 트리를 큰 트리에 붙이기 위함)
public:
DisjointSet(int n) { // vertex 개수 n만큼 배열을 초기화하는 생성자
parent.resize(n);
rank.resize(n, 0); // 모든 트리의 초기 depth는 0
for (int i = 0; i < n; i++) // 각 vertex를 자신만 포함하는 독립된 집합으로 초기화
parent[i] = i;
}
int find(int x) { // vertex x가 속한 집합의 루트를 찾는 재귀함수
if (parent[x] != x)
parent[x] = find(parent[x]); // 경로 압축(구조 기반 캐싱)
return parent[x];
}
void unite(int x, int y) { // 두 집합을 병합하는 함수
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) // 같은 집합에 속해 있다면
return;
if (rank[rootX] < rank[rootY]) // 작은 트리를 큰 트리 밑으로 붙여 트리의 높이를 최소화
parent[rootX] = rootY;
else {
parent[rootY] = rootX;
if (rank[rootX] == rank[rootY])
rank[rootX]++;
}
}
};
// 크루스칼 알고리즘
void kruskal(const vector<Edge>& edges) {
DisjointSet ds(V);
vector<Edge> MST;
int totalWeight = 0;
vector<Edge> sortedEdges = edges;
sort(sortedEdges.begin(), sortedEdges.end(), compare);
for (const Edge& e : sortedEdges) {
if (ds.find(e.u) != ds.find(e.v)) {
MST.push_back(e);
totalWeight += e.weight;
ds.unite(e.u, e.v);
if (MST.size() == V - 1)
break;
}
}
cout << "선택된 간선들(u - v : weight):\n";
for (const Edge& e : MST)
cout << "V" << e.u + 1 << " - V" << e.v + 1 << " : " << e.weight << "\n";
cout << "총 가중치 : " << totalWeight << "\n";
}
int main() {
// 인접 행렬 (INT_MAX는 edge가 없음을 의미)
int W[V][V] = {
{0, 1, 3, INT_MAX, INT_MAX},
{1, 0, INT_MAX, 6, INT_MAX},
{3, INT_MAX, 0, 4, 2},
{INT_MAX, 6, 4, 0, 5},
{INT_MAX, INT_MAX, 2, 5, 0}
};
// 인접 행렬 -> 간선 리스트로 변환
vector<Edge> edges;
for (int i = 0; i < V; i++) {
for (int j = i + 1; j < V; j++) {
if (W[i][j] != INT_MAX) {
edges.push_back({i, j, W[i][j]});
}
}
}
kruskal(edges);
return 0;
}
🔽 출력 :
선택된 간선들(u - v : weight):
V1 - V2 : 1
V3 - V5 : 2
V1 - V3 : 3
V3 - V4 : 4
총 가중치 : 10
참고로 크루스칼 알고리즘의 시간 복잡도는 edge의 개수에 따라 크게 달라지는데, 그 이유는 edge를 가중치 기준으로 정렬하는 데 걸리는 시간에 있다.
엄밀히는, edge 정렬 시간과 find / union 연산 시간, 2단계에 걸친 시간이 소요되는데 각 edge마다 find()와 union()을 수행하는 데 걸리는 시간은 상수 시간에 가깝다.
따라서 크루스칼 알고리즘의 basic operation은 edge 정렬 시간이다.
이에 따라 알고리즘의 시간 복잡도가 edge가 적을 때는 Θ(nlogn)부터, edge가 많을 때는 Θ(n^2logn)까지 늘어난다.
n X n 그래프에서 모든 edge가 있는 완전 그래프인 경우 n^2개의 edge를 정렬해야 하기 때문이다. 참고로 비교 기반 정렬 알고리즘의 lower bound는 Θ(nlogn)이다.
edge가 적으면 크루스칼, edge가 많으면 프림의 알고리즘이 더 좋지만, 사실 프림의 알고리즘에서 피보나치 힙 자료구조를 사용하면 항상 Θ(nlogn)을 유지하므로 프림의 알고리즘이 더 좋긴 하다.
마무리
프림의 알고리즘은 정점 중심 확장
크루스칼의 알고리즘은 간선 중심 선택
그래프의 특성(정점 수, 간선 수 등)에 따라 더 적합한 알고리즘을 선택할 수 있다.
Leave a comment