
[데이터베이스] B+Tree 인덱스
앞선 해시 인덱스는 O(1)의 빠른 검색이 가능하지만, 다음과 같은 한계 가 있었다.
- 정렬이 안 되어 있어서 범위 검색(Range Query) 불가
<,>,BETWEEN같은 조건에서 활용 어려움- ORDER BY , GROUP BY 등에 사용 불가
이 한계를 극복하는 인덱스 구조가 바로 B+Tree 인덱스 이다.
B+Tree 인덱스란?
B+Tree 는 균형 잡힌 다진 트리(Balanced M-ary Tree) 구조로, 대부분의 관계형 데이터베이스(RDBMS) 에서는 기본 인덱스 자료구조로 B+Tree를 사용한다.
MySQL,PostgreSQL,Oracle,SQL Server등 거의 모든 DBMS에서 기본 인덱스로 채택하고 있다.
주요 특징
- 모든 데이터(실제 값)는 리프 노드 에만 저장됨
- 리프 노드는 오름차순으로 정렬 되어 있으며, 연결 리스트 형태로 이어져 있음
- 리프 노드가 아닌 내부 노드(Internal Node)는 탐색을 위한 키 값만 저장
- 트리 전체가 균형(Balanced) 을 유지하므로, 모든 리프 노드의 깊이가 동일함 → 탐색 시간
O(logn)
B+Tree 구조 살펴보기
위 사이트에서 B+Tree를 조작해볼 수 있다.
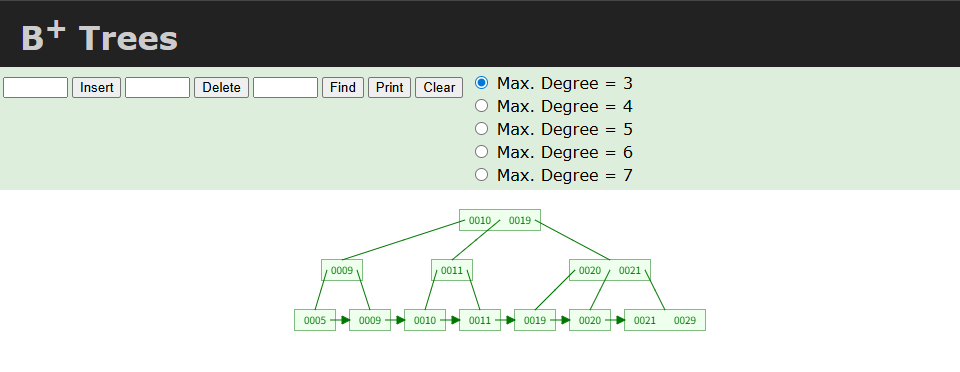
위 트리 구조에서 여러 노드 중 실제 데이터를 가지는 노드는 리프 노드밖에 없다.
그 외의 노드들은 내부 노드(Inner Node)로, 탐색을 위한 키 값과 키 값에 따른 분기 방향만을 제시할 뿐이다. 또한 리프 노드 간에는 오른쪽으로 연결된 포인터가 존재하고, 이 포인터로 인해 범위 탐색에 유리해진다.
리프 노드에서 실제 값의 용량이 큰 경우 실제 값을 가리키는 주소(포인터)만 저장해서 사용하기도 한다.
이러한 구조 덕분에 정렬된 순서로 데이터를 순회할 수 있게 된다.
B+Tree 인덱스의 작동 방식
✅ 탐색(Search)
- 루트 노드부터 시작하여 내부 노드를 타고 내려간다. 각 내부 노드에는 여러 개의 키 값이 저장되어 있으며, 찾으려는 키와 비교하여 적절한 자식 노드로 이동한다.
- 찾는 값이 현재 키보다 작으면 왼쪽 자식으로, 같거나 크면 오른쪽 자식으로 이동한다.
- B+Tree는 이진 트리가 아닌 다진 트리 이므로, 한 번에 더 많은 범위를 탐색할 수 있다.
- 리프 노드에 도달하면 해당 키를 찾고, 필요한 값을 가져온다.
✅ 삽입(Insert)
- 새로운 키를 리프 노드에 삽입한다.
- 리프 노드가 꽉 차면 Split(분할) 이 발생하고, 부모 노드에 분기 기준이 되는 중간 키를 전달한다.
- 만약 부모 노드도 꽉 차면 상위 노드로 재귀적인 Split이 발생한다.
✅ 삭제(Delete)
- 리프 노드에서 키를 제거한다.
- 제거하기 전에 노드 안에 키 값이 절반 이상 차있는지 확인 후 절반 이상 차있으면 바로 삭제가 일어나고, 절반 이상 차있지 않으면 sibling으로부터 노드를 빌리거나 빌릴 수 없는 경우 merge하여 항상 정렬된 상태와 노드의 균형을 수호한다.
B+Tree 인덱스의 장점
| 장점 | 설명 |
|---|---|
| 정렬 유지 | 키가 항상 정렬되어 있어 범위 쿼리에 최적 |
| 빠른 탐색 | O(logn) 시간 복잡도 |
| 범위 탐색 최적 | 리프 노드가 연결 리스트로 이어져 있어 연속 데이터 탐색이 효율적 |
| 디스크 접근 최적화 | 블록 단위로 구성되어 있고, 한 블록에 여러 키가 저장됨 → 디스크 I/O 감소 |
B+Tree 인덱스가 사용되는 예시
-- 이름이 '박'씨인 사람들 검색
SELECT *
FROM users
WHERE name LIKE '박%';
-- 날짜 범위 조회
SELECT *
FROM orders
WHERE created_at BETWEEN '2025-07-01' AND '2025-07-31';
-- 정렬 기반 페이징
SELECT *
FROM posts
ORDER BY create_at LIMIT 10 OFFSET 20;
-- 이상, 이하 조건
SELECT *
FROM employees
WHERE salary >= 5000;
해시 인덱스로는 불가능한 범위/정렬 기반 연산을 효율적으로 처리할 수 있다.
B+Tree vs Hash Table
| 기준 | B+Tree 인덱스 | 해시 인덱스 |
|---|---|---|
| 검색 속도 | O(logn) | 평균 O(1), 최악 O(n) |
| 정렬 유지 | 가능 | 불가능 |
| 범위 검색 | 가능 | 불가능 |
| 삽입/삭제 후 균형 유지 | 자동 | 직접 관리 필요 |
| 기본 인덱스 채택률 | 대부분의 DBMS에서 사용 | 일부 NoSQL에서만 사용 |
해시 인덱스는 동등 비교(=)에 특화, B+Tree 인덱스는 정렬·범위·다양한 연산에 강한 범용 인덱스이다.
마무리
B+Tree는 정렬된 데이터 접근, 범위 쿼리, 다양한 조건식 처리, 디스크 접근 효율성까지 고루 갖춘 인덱스 구조로, 대부분의 관계형 데이터베이스에서 기본 인덱스 구조로 사용된다.
Leave a comment